Service, Ingress, and Service Mesh: When Kube-Proxy Isn’t Enough


It’s been a long time since Kubernetes came into the industry and has been the de-facto choice for every company when it comes to choosing a container orchestrator to run their mission-critical workload. And if I asked you about one object which is the heart of everything running in Kubernetes, then most probably your finger would point to the Service object which makes your application discoverable within the cluster.
The Service is the primary object through which services within the cluster discover each other, and the endpoint is backed by CoreDNS, so how does request flow typically look here?
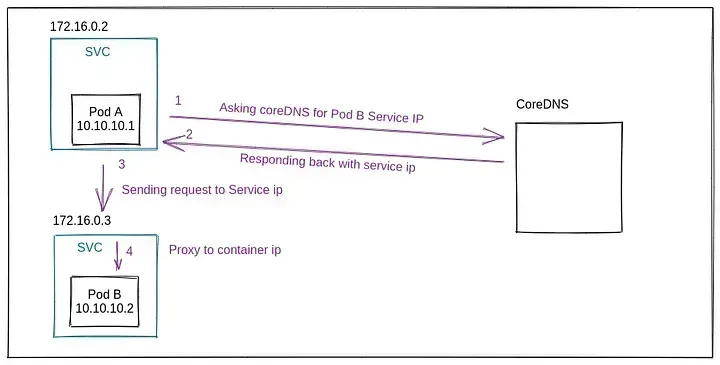
Figure 1 — Service to Service Flow in k8s
So, that’s the typical flow of how service-to-service communication previously worked, as shown in Figure 1. Don’t get crazy that I used the word “worked” above. 😯
It’s likely that you are asking yourself, “Has Kubernetes changed the core nature of how the services communicate with one another ?”

Not quite, and that is what we will talk about today. Let’s get started
Here, we’ll take a closer look at two scenarios to demonstrate when Kube-proxy, also known as service, is no longer used for service communication.
- communication when Service-Mesh is involved (not sure if we would be able to cover this in this blog itself)
- communication when Ingress Controller is involved
Communication when Ingress Controller is involved
If you’re not sure of what an ingress controller is, have a look at the quoted sentence; it should provide you with some foundational definitions.
Ingress controller with the help of ingress object lets you expose your application to the outside world, There are many ingress controllers available like Nginx Ingress controller, Kong, Traefik and Istio etc
Let’s give you a visual representation of what an ingress/ingress controller would look like in action.
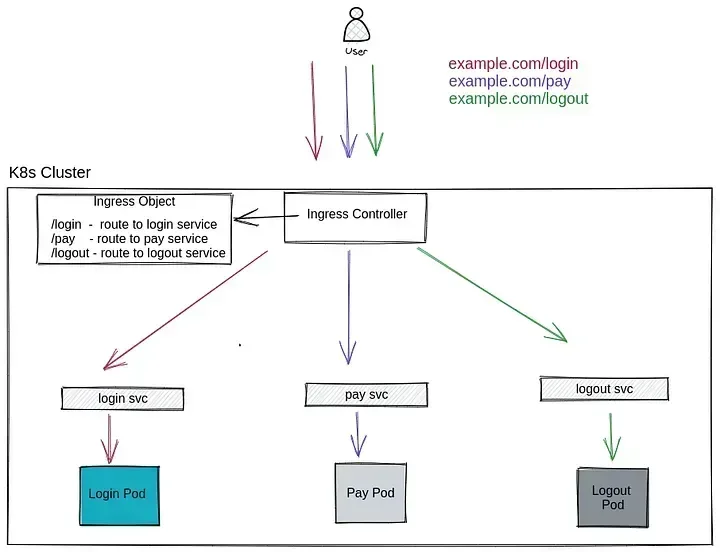
Figure 2 — communication from ingress using service
This diagram pretty much explains what is going on here. When a user attempts to connect to example.com using various different path-based APIs, the request first reaches the ingress controller (which could be any ingress controller here), then the ingress controller makes some calculations regarding which API should be forwarded to which service based on the ingress object configuration, and finally the service sends the traffic to the actual container IP based on the iptable rules in that particular node.
One thing is certain: the Ingress controller has no idea if there are 1 container or 100 containers behind the service since traffic will always be forwarded to the service endpoint by the Ingress controller. This is what we have observed thus far, and we have learned that this is how communication works.
I hope we are now on the same page with regard to what I just explained.
But this is when things start to get interesting.
What if I told you that the majority of controllers no longer forward traffic to service endpoints in order to access containers since this method of communication has become outdated?
If you’re scratching your brain and thinking, “What is being used by the controller if not service ?” 🤔 🤔 🤔
Let’s talk about this.
Ingress controllers have advanced significantly in recent years and have been set up to use Kubernetes APIs to help them make better decisions. And that’s where the magic comes from.
Just take a quick glance at the diagram below, and we’ll explain what’s going on after that.
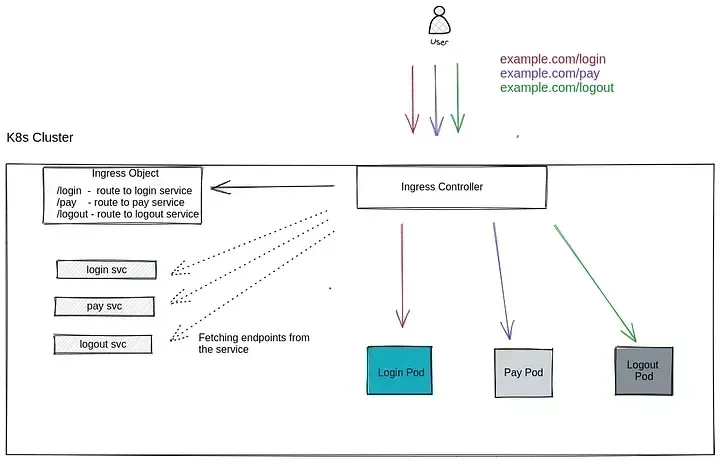
Figure 3 — communication from ingress without service
The Figure 2 diagram that we previously discussed is very different from this one.
We can see that the service object has been removed from the communication path, and the ingress controller is now sending traffic straight to the application rather than via a service endpoint.
You’re probably wondering how the ingress controller will know about the new container and how it will determine which service the container belongs to given that the container is mutable. What happens if the container goes down and a new container with a new IP appears?
Let’s clear up this mystery piece by piece.
- Instead of sending traffic to a service endpoint during this time, traffic that matches a specific path is sent directly to the application container IP because the ingress controllers have all the ips in place as configured in the backend object.
- The ingress controller then continuously checks to see if there have been any changes to the service endpoints in the event that a container has been restarted/killed or a new container is started.
- The controller then fetches all container endpoints from that specific service object it sees in ingress by calling the service endpoint API and generating a config with all those container ips defined as backend.
- The ingress controller reads the ingress object to determine which type of traffic should be forwarded to which service (we still use the term “service” in the ingress object).
I believe this helps to illustrate how the method of communication has changed, particularly from ingress controllers to its downstream services.
However, we are not yet finished, and I can assume that you will probably have a lot of questions in your mind right now, such as
- Does it mean we no longer require service in Kubernetes?
No, service is still an integral component of communication. If there were no ingress controller and internal services were communicating with one another, they would still only be able to connect to one another via a service endpoint.
- What happens to Kube-proxy?
As I previously stated, if there is no ingress controller, you will need a service endpoint; hence, Kube-proxy will also be required in that situation.
- What caused this change in the ingress controller’s behavior, and why?
That’s really important to understand why that was required in the ingress controller when the service endpoint was doing its job perfectly.
Although it is well known that Kubernetes services serve as a dump proxy, sending traffic to downstream ips in a round-robin fashion and that ingress controllers, such as the Nginx ingress controller, Kong, Traefik, or Istio, are the most popular proxies and load balancers with sophisticated load-balancing strategies, they are worthless if we use service endpoints between the controller and the application container since the controllers would never be able to use advanced load balancing capabilities because traffic would always go to the same IP address (service endpoint), regardless of how many containers were running behind the service endpoint.
Why not create a system that detects how many IP addresses are hidden behind a service, extracts those IP addresses that belong to containers, changes the controller’s routing configuration, and starts sending traffic to the container itself?
And that’s what all ingress controllers (at least Nginx/Istio/Traefik ) did in order to be able to leverage their built-in load-balancing capabilities.
Final Thoughts !!
Service is and always will be a fantastic object, but it is insufficient for ingress controllers and was beginning to impede their ability to leverage their inherent capabilities.
Even though the load balancing capability of the service endpoint is sort of becoming obsolete, the service object will always be there because it is still the source of truth for ingress controllers to retrieve all of the available container ips.
I’m hoping this blog will be useful in understanding the changes we have witnessed in service evolution so far.

Till the next time — Happy learning :)